


Spark adalah mesin yang digunakan untuk analisis dan pemrosesan data dalam skala besar Pada dasarnya, Spark bukanlah versi modifikasi dari Hadoop dan tidak bergantung pada Hadoop karena memiliki manajemen cluster sendiri. Hadoop hanyalah salah satu cara untuk mengimplementasikan Spark. Spark menggunakan Hadoop dalam dua cara - penyimpanan dan kedua adalah pemrosesan. Karena Spark memiliki komputasi manajemen klasternya sendiri, ia menggunakan Hadoop hanya untuk tujuan penyimpanan.
Spark SQL
Modul apache spark yang digunakan untuk mengerjakan data terstruktur.
Arsitektur Spark SQL
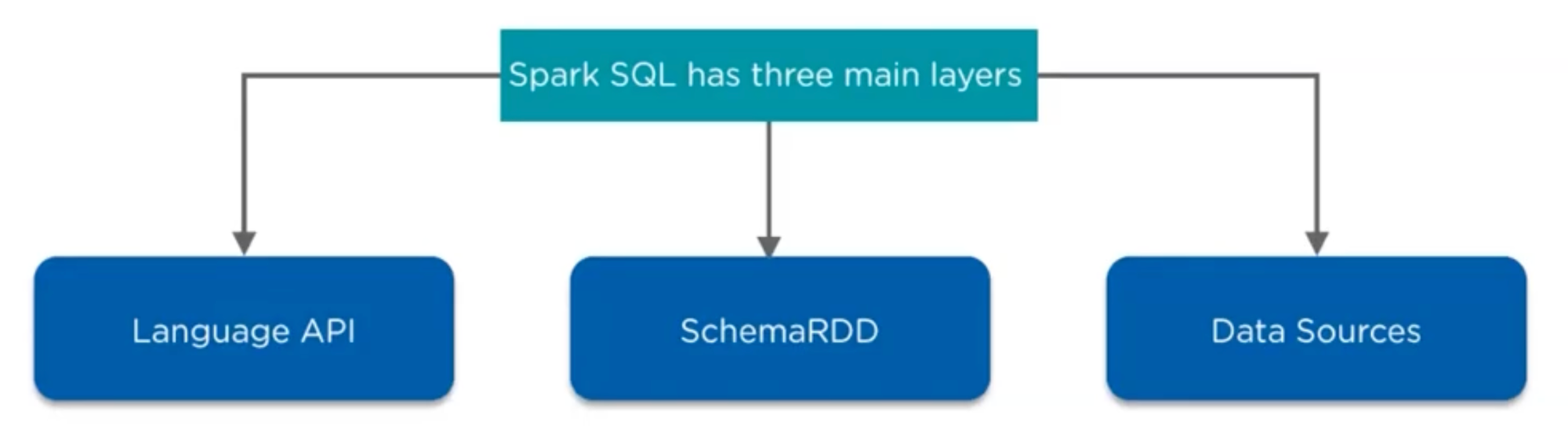
Language API
Spark support beberapa bahasa yaitu sql, python, scala, java, HQL. Setiap language API dapat diakses menggunakan CLI. Menjalankan spark bisa menggunakan beberapa command command
Bash
Copy
# Spark menggunakan scala & java
spark-shell
# Spark menggunakan sql
spark-sql
# Spark menggunakan python
pyspark
# Spark menggunakan R
sparkR
Ada 3 Komponen Fundamental yaitu
Spark Context dapat diakses menggunakan command `sc`
Spark Session (kumpulan dari spark context, hive context dan sql context). Baru ada di Spark2. Dapat diakses menggunakan command `spark`
Spark UI dapat di akses di http://localhost:4040
Schema RDD
Di spark ada beberapa jenis data
RDD (Resilient Distributed Dataset)
Bersifat immutable dan type safe.
RDD memiliki beberapa sifat contohnya Transformation (map, flatMap, sortby, filter, dsb) dan Action (reduce, agregate, take, foreach, dsb).
RDD mengoptimize pekerjaan sampai program melakukan Action jadi pekerjaan-pekerjaan lain yang tidak berkaitan tidak akan dikerjakan.
DataFrame
Bersifat immutable dan tidak type safe.
Dapat melakukan pemrosesan dengan lebih mudah dibanding RDD karena DataFrame menyimpan data dalam bentuk tabel dan memiliki beberapa API untuk membantu pengolahannya.
DataFrame bersifat tidak Type Safe sehingga pada beberapa kasus developer yang lupa tipe datanya melakukan kesalahan dan menyebabkan program error.
Dataset
Penyimpanan data yang menggabungkan keunggulan DataFrame dan RDD. Menyimpan data dalam bentuk tabel, memiliki beberapa API untuk memudahkan pemrosesan, dan bersifat Type Safe.
Data Sources
Spark sql support Parquet file, JSON document, HIVE tables, and Cassandra database.
Catalyze Optimizer
Mekanisme optimasi based on scala dengan tujuan untuk solving data besar dan mempermudah developer untuk custom function terkait optimizer.
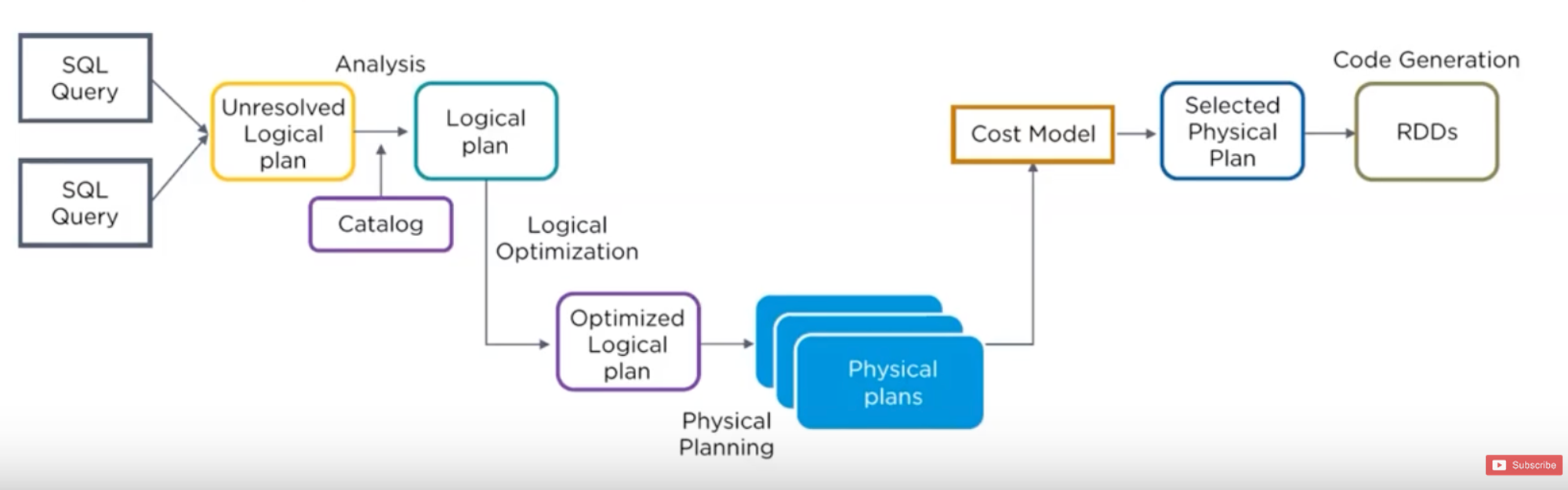
FLOW
Analisis
Analisis dilakukan oleh 2 cara
SQL Parser membentuk AST (Abstract Syntax Tree).
DataFrame dari Spark SQL API
Logical Optimization
Rules untuk optimasi di set di logical plan.
Rules juga dapat ditambahkan.
Physical Planning
Dari Logical plan dan menggenerate 1 / banyak physical plan menggunakan physical operator sesuai spark execution engine. Plan akan dipilih berdasarkan cost based model (Perbandingan model cost tiap plan).
Code Generation
Generate Java Bytecode.
Contoh Catalyst Optimizer
Query →
Bash
Copy
// Business object
case class Persona(id: String, nombre: String, edad: Int)
// The dataset to query
val peopleDataset = Seq(
Persona("001", "Bob", 28),
Persona("002", "Joe", 34)).toDS
// The query to execute
val query = peopleDataset.groupBy("nombre").count().as("total")
// Get Catalyst optimization plan
query.explain(extended = true)
Java Bytecode →
Bash
Copy
== Analyzed Logical Plan ==
nombre: string, count: bigint
SubqueryAlias total
+- Aggregate [nombre#4], [nombre#4, count(1) AS count#11L]
+- LocalRelation [id#3, nombre#4, edad#5]
== Optimized Logical Plan ==
Aggregate [nombre#4], [nombre#4, count(1) AS count#11L]
+- LocalRelation [nombre#4]
== Physical Plan ==
*(2) HashAggregate(keys=[nombre#4], functions=[count(1)], output=[nombre#4, count#11L])
+- Exchange hashpartitioning(nombre#4, 200)
+- *(1) HashAggregate(keys=[nombre#4], functions=[partial_count(1)], output=[nombre#4, count#17L])
+- LocalTableScan [nombre#4]