

Cassandra Read Path
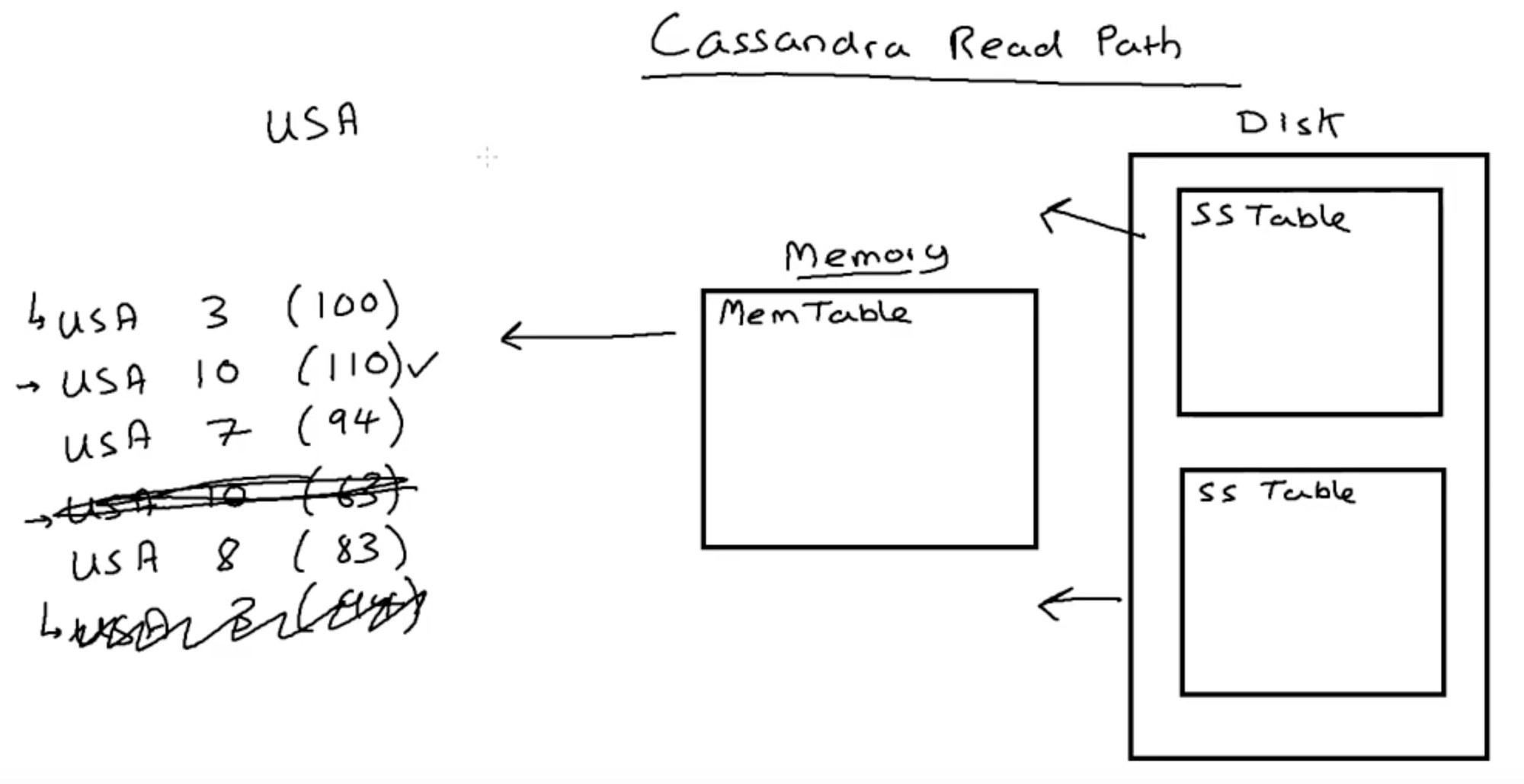
Untuk membaca data dari Cassandra, Cassandra akan mencari data dari dua tempat yaitu MemTable dan SS Table. Prosesnya dimulai dengan mengambil data dari MemTable dan kemudian mencari di SS Table. Jika ada data dengan Clustering Column yang sama, Cassandra akan memilih data dengan timestamp yang terbaru. Setelah data berhasil dibandingkan dan dipilih, Cassandra akan mengirimkan data tersebut ke client.
Sistematika Penyimpanan Data di SS Table

Ketika data disimpan, data tersebut telah diurutkan dan diindeks dengan pembatas antara tiap kunci partisi. Misalnya, kunci partisi "Japan" dimulai dari 1000, "EU" dimulai dari 1001 hingga 2000, dan seterusnya. Oleh karena itu, ketika melakukan pencarian untuk kunci partisi "China", tidak perlu memulai dari indeks 0 tetapi langsung dari 2001.
Sistematika Searching Data di SS Table

Bloom Filter berfungsi untuk dua hal:
Menentukan dengan pasti bahwa sebuah data tidak ada pada SS Table.
Menentukan kemungkinan besar sebuah data ada pada SS Table.
Key Cache digunakan untuk menyimpan byte location dari Partition Key yang sering diakses. Misalnya, China 2000 dan Brazil 2600.
Partition Index adalah seperti Key Cache, namun berisi indeks dari semua partisi (tidak hanya yang sering diakses).
Partition Summary adalah kelompok partisi yang terindeks, misalnya Jepang, Eropa, dan Cina di satu kelompok, dan Amerika Serikat, Brasil, dan Australia di kelompok lainnya.
SS Table digunakan jika belum ada pengindeksan sebelumnya.